Scaling Render Services
Run multiple instances to handle additional load.
You can run multiple instances of a web service, private service, or background worker to handle additional load. For services that receive incoming traffic, Render load balances that traffic evenly across all running instances:
Each instance of a scaled service uses the same instance type and is billed accordingly. You can scale each service up to a maximum of 100 instances.
Render supports two scaling methods: manual scaling and autoscaling.
| Scaling Method | Description |
|---|---|
|
Render runs a fixed number of instances that you specify. Manual scaling is available for all Render workspaces. | |
|
Available only for Professional workspaces and higher. Render automatically scales your number of instances between a specified minimum and maximum, based on target CPU and/or memory utilization. |
Manual scaling
You can manually scale your service to any fixed number of instances, up to a maximum of 100.
-
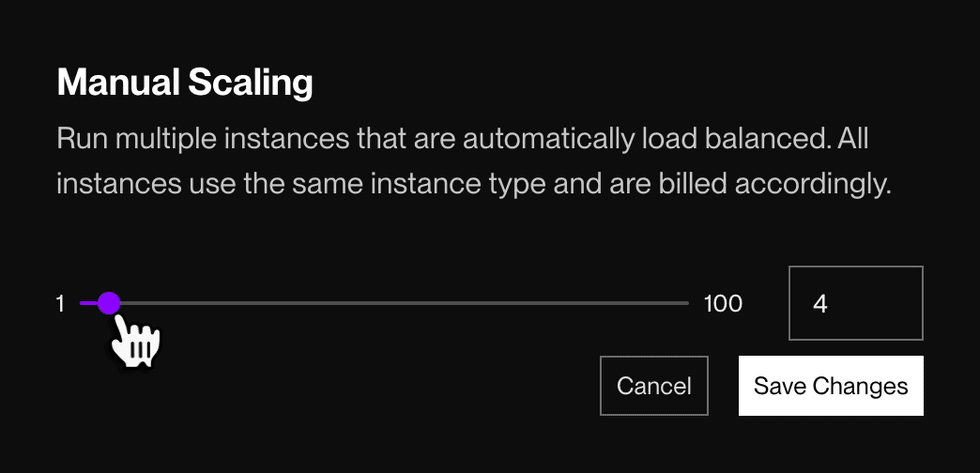
In the Render Dashboard, open your service’s Scaling page and scroll down to the Manual Scaling section:
-
Drag the slider to the desired number of instances, or enter a value between
1and100in the text box. -
Click Save Changes.

Render immediately provisions or deprovisions instances as needed to match the new instance count.
Manual scaling events appear in the timeline on your service’s Events page:

Autoscaling
Autoscaling requires a Professional workspace or higher.
Render can automatically scale your service up and down based on CPU and/or memory utilization targets that you specify. This helps you handle periods of high traffic while also minimizing compute costs.
Enable autoscaling for your service from its Scaling page in the Render Dashboard:

-
Use the slider to set your desired minimum and maximum instance count, or enter a value in each text box.
- Render always keeps your instance count within the specified range, even if resource utilization is significantly below or above your specified target.
-
Scroll down to set your target CPU and/or memory utilization:
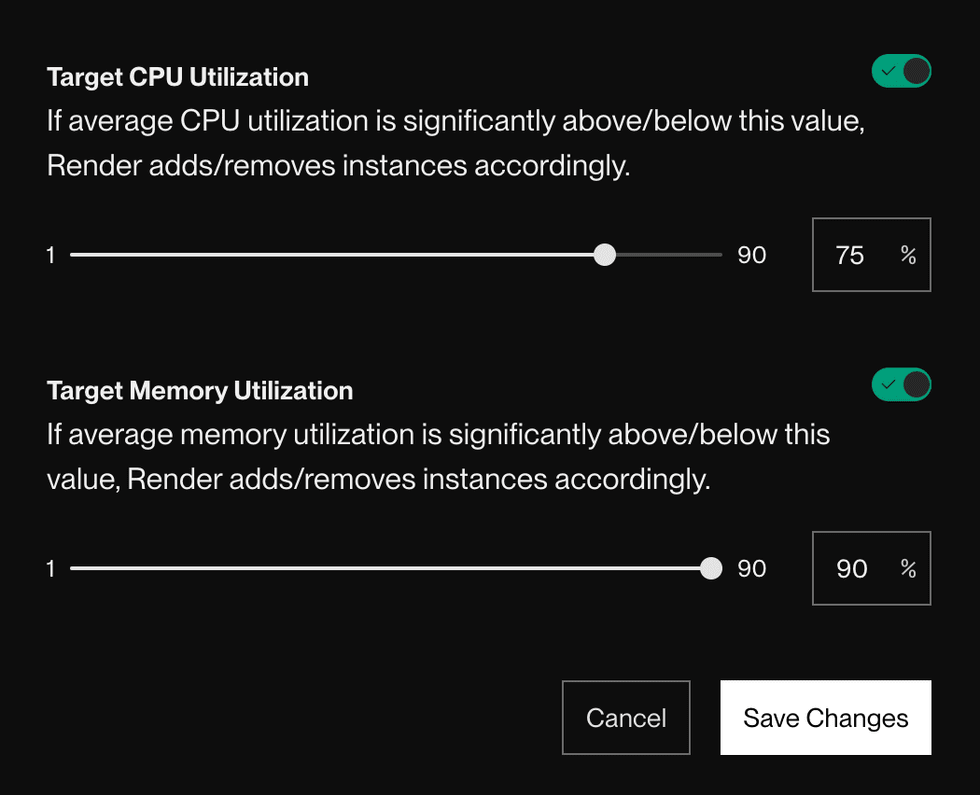
Enable one or both of the toggles and set your target utilization percentage(s).
If you enable neither toggle, autoscaling is disabled for the service.
-
Click Save Changes.

Render begins monitoring resource utilization and automatically scales your service up or down as needed based on your specified targets.
Autoscaling events appear in the timeline on your service’s Events page:

How autoscaling works
Render periodically calculates average resource utilization across all instances of your autoscaled service. Using that value (current_util), Render determines whether to scale your service based on the following formula:
new_instances = ceil[current_instances * (current_util / target_util)]If new_instances doesn’t equal current_instances, Render scales your service up or down to the new instance count.
Render waits a few minutes before scaling a service down.
If utilization rises again during this period, Render does not scale the service down. This minimizes unnecessary scaling actions during periods of “spiky” usage.
Render always scales a service up immediately to handle increased load.
Example 1: Scaling up
| Current instances | Current CPU | Target CPU |
|---|---|---|
| 2 | 80% | 60% |
new_instances = ceil[2 * (80% / 60%)] = 3In this scenario, Render immediately scales the service up from 2 instances to 3.
Example 2: Scaling down
| Current instances | Current Memory | Target Memory |
|---|---|---|
| 5 | 20% | 60% |
new_instances = ceil[5 * (20% / 60%)] = 2In this scenario, Render waits a few minutes, then scales the service down from 5 instances to 2 if memory utilization remains low.
If you set targets for both CPU and memory utilization, Render calculates new_instances based on each and uses the larger result.
Billing for scaled services
Billing for a scaled service is based entirely on compute usage, which is prorated by the second. There is no additional cost for performing a scaling action.
Here are some example scenarios:
| Scenario | Billing Result |
|---|---|
| You run exactly two instances of a service for an entire month. | You’re billed for 2x the monthly price of your service’s instance type. |
| Exactly halfway through a month, you manually scale your service from two instances down to one. It remains at one instance for the rest of the month. | You’re billed for 1.5x the monthly price of your service’s instance type. |
| Every day of a month, your service autoscales from one instance to two for exactly six hours. It then autoscales back down to one instance. | You’re billed for 1.25x the monthly price of your service’s instance type. |
See your exact compute usage for the month on your Billing page. You can also review your invoice history.
Application considerations
-
Services with an attached persistent disk cannot scale to multiple instances.
-
You can update your service’s scaling configuration programmatically via the Render API.
- Separate endpoints are available for manual scaling and autoscaling.
-
If you configure both manual scaling and autoscaling for a service, Render enables autoscaling and ignores the manual scaling configuration.
Horizontal vs. vertical scaling
The sections above describe Render’s support for horizontal scaling, where you adjust a service’s number of running instances.
In contrast, vertical scaling refers to adjusting a service’s compute resources (RAM and CPU). You vertically scale a service by changing its instance type in the Render Dashboard.
When to use each
- Scale horizontally to handle a higher number of simultaneous tasks (such as incoming requests).
- Scale vertically if each single task requires additional RAM or CPU to run efficiently.
- For particularly resource-intensive tasks, consider offloading to a background worker to keep your web services responsive.
Horizontal scaling usually occurs much more frequently than vertical scaling. Autoscaled services might change their instance count multiple times per day, whereas you might upgrade a service’s instance type once in a year.